微博
-

我曾以为我是这个世界的主角。 修仙世家出身,千年难遇的奇才,名门大派的道子。
为了那个“飞升”的梦,我斩断尘缘,枯坐千年,九死一生抗下雷劫。
当接引仙光落下时,我以为我赢了。
可现在,我站在十万大军的方阵里,像一颗不起眼的尘埃。 看着那个只有几十岁骨龄的猴子,把天捅了个窟窿。
这一刻我才懂: 我的终点,名为“天兵乙”。 而这,仅仅是他的起跑线。
评论 -
😂😂😂

-
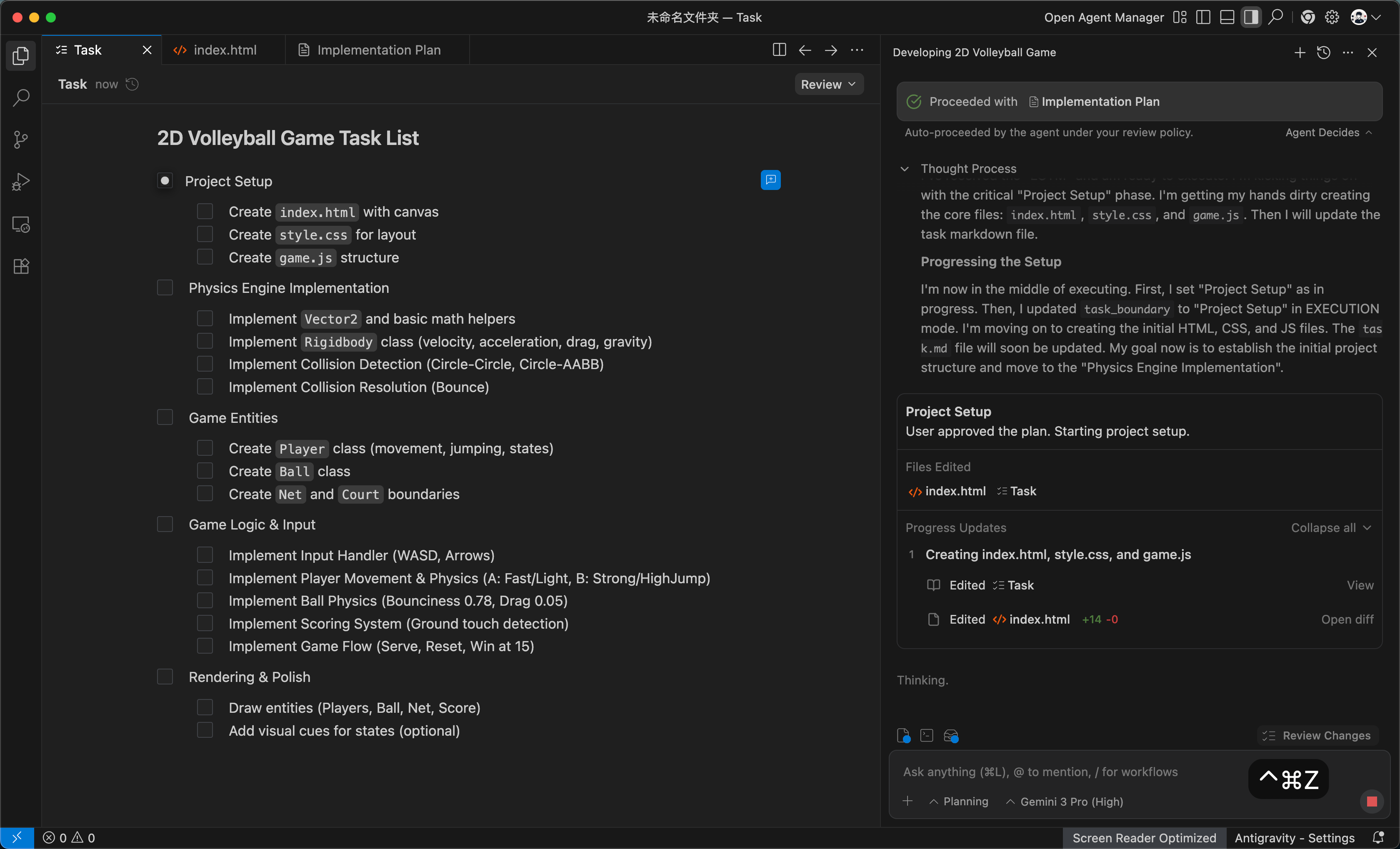
Google 收购了 Windsurf 后推出了套壳 Antigravity AI IDE,Vibe Coding 生态补齐,完全对标 Anthropic 和 OpenAI,模型方面配合内置 Gemini 3 Pro 和 Nano Banana,无脑写前端,更爽了
链接直达
-
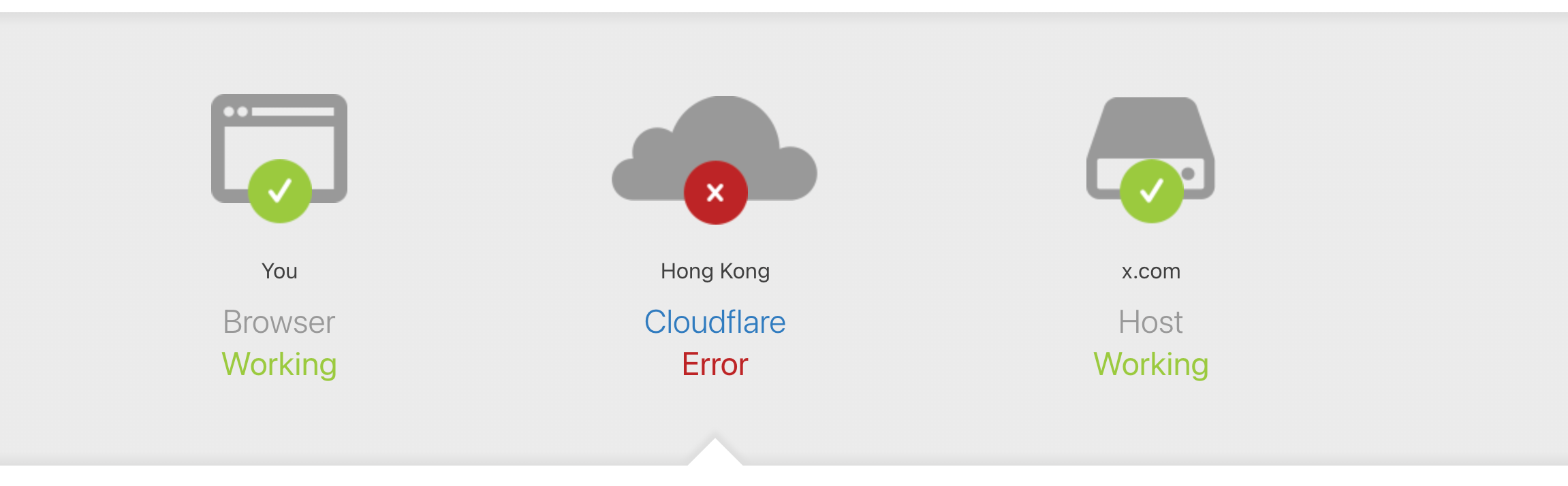
cf 一炸,全球互联网一半都被炸了吧 😂😂😂
-
真正的智能,不是让 AI 取代人,而是让人与 AI 各司其职。
在 AI 时代,最宝贵的不是会写代码的人,核心是知道要写什么代码、以及如何写出好代码,这样的人才拥有核心竞争力,才不会被淘汰。
大模型的 80 分危机
大模型在 vibe coding 领域明显表现出的
超强起手特征。这种效率提升是革命性的,但瓶颈也随之而来。它的瓶颈来自于大模型能轻易地将一个项目从 0 分做到 80 分,但从 80 分提升到 95 分以上的生产水准,却异常艰难。
我们会发现它擅长的快速生成基础代码框架、搭建网站原型、编写业务逻辑初稿,它拥有扎实的技术功底,却对业务背景和代码历史一无所知,所以评分却只能到达 80 分,而从 80 分到 95 分+ 是必要人去介入调优,而这一步却困难重重,需要大模型拥有基于现有信息去深入理解业务规则的能力、复杂的边界判定、性能优化、故障预案等,这不仅涉及到对现状的深入理解、还需要庞大的上下文支撑,同时需要人来引导大模型。核心是在于为 AI 提供精确的上下文信息。提供的背景越详实,AI 需要
猜测的部分就越少。精确的上下文虽不能保证完全正确的结果,但模糊的上下文必然导致模糊的产出。新角色:大模型善后工程师 -
人类专家大模型能
秒出框架,但框架之后的那片沼泽地,依然是需要人要去跋涉的。人类专家的工作就是专门负责处理由大模型生成的 80 分代码,将其打磨至上线的专业标准。本质上,他们是连接大模型快速产出与专业交付标准之间的桥梁,是弥补大模型在处理复杂、高标准项目时能力短板的关键角色,这一定是未来趋势,需要我们去思考:大模型没有淘汰程序员,而是重新定义了开发工作流。80 分危机和大模型善后工程师的出现,正是技术演进过程中的自然调整。 -
一个隐藏但普遍的严峻问题:当 Agent 需要访问的 MCP 工具数量从几个增长到成百上千时,传统的直接工具调用模式存在效率瓶颈。
Anthropic 提出让模型写并执行代码的 Code Mode 来优化 MCP,将范式从
工具调用者转变为代码编写者。大模型相比理解工具调用更理解代码的编写,从而极大节约 token、提高效率并改善隐私控制。具体实现原理:把 MCP servers 呈现为代码 API(例如 TypeScript 文件树)而不是直接的工具调用接口。Agent 的任务不再是选择工具并填充参数,而是编写代码来完成整个工作流。指令下给模型任务,模型生成代码来调用这些 API,代码在受控(沙箱)执行环境中跑,数据在环境里过滤/聚合后把浓缩/脱敏结果返回给模型。
Cloudflare 也用了类似想法并称其 “Code Mode”。
-
Chrome 分屏视图布局上线了

-
魏翔的《时差》太洗脑了,循环播放了

-
SRE 可观测性领域涉及时序预测学科中(AIOps)传统算法,例如统计学算法、机器学习算法、深度学习算法等,会被大模型取代吗?
过去几年,企业尝试通过 AIOps 平台 实现告警聚合与根因分析,AIOps 停留在“统计智能”阶段,而 Agent 正在迈向“认知智能”阶段。原因是:AIOps 只能告诉你“CPU 异常”,而 Agent 能理解为什么 CPU 异常,以及是否需要立即干预。
当然传统算法仍然无法替代,我们需要快速、低成本、准确响应,传统算法可以解决 80% 的场景,这类场景既然“杀鸡不用牛刀”,也没有必要动用计算开销巨大的大模型来处理这些问题。
当然大模型比传统的异常检测算法的明显优势是多源信息关联、语义理解与因果推理能力,这也是传统算法无法做到的,两者是互补的存在,相辅相成,所以我们需要根据场景来合理利用。
链接直达
AI 时代可观测性的“智”变与“智”控 |InfoQ《极客有约》
三大头部互联网企业交锋,AI时代可观测边界出现了吗? -
6 周年快乐哦 🌹🌹🌹 @小陈同学
